Controlling my heating with Home Assistant
My original post about home automation discussed the fact that one of my motivations was improving control over my central heating system. In the last few weeks I’ve finally brought enough pieces together to make that a reality. My boiler is controlled by a Siemens RCR10/433 thermostat. Ross Harper has a good write-up about decoding the Siemens RCR10/433 and I was able to extend my Energenie Atmel 433MHz transmitter to treat the boiler as another switch. Slightly different timing than the Energenie switches, but exactly the same principle. My TEMPer USB clone provides a reading of the living room temperature. Finally mqtt-arp lets me work out whether anyone is home or not.
Everything is tied together with Home Assistant. The configuration has ended up more involved than I expected, but it’s already better than the old 24 hour timer. There’s definitely still room for improvement in terms of behaviour as the weather starts to get colder and I collect further data. Presently it looks like this:
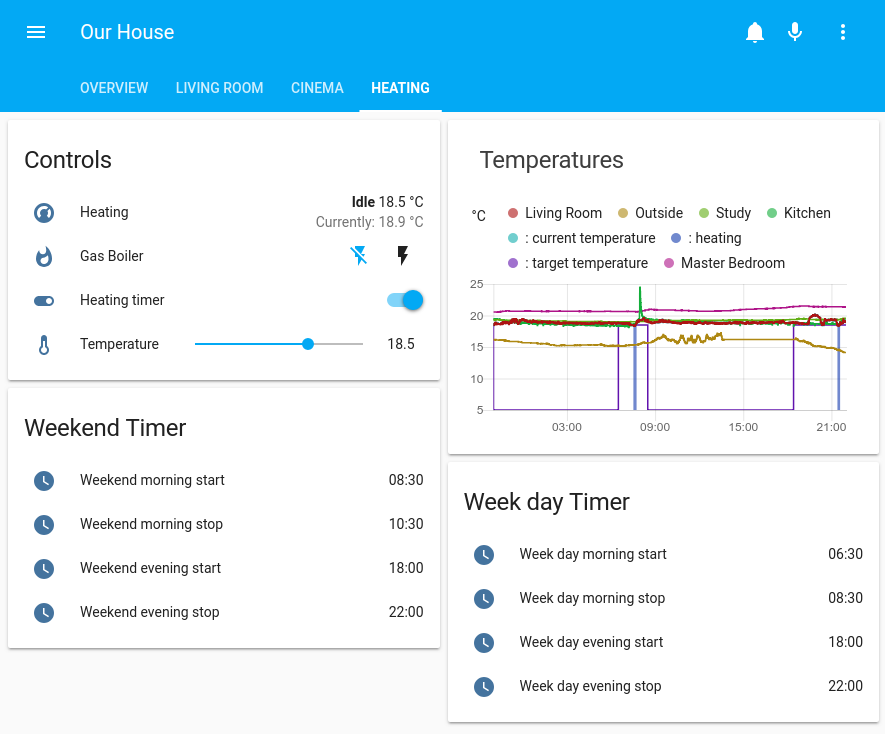
Top left is the control card; “Heating” is a climate control with a target temperature and a current temperature (from the living room sensor), an on/off state for the boiler (linked to the 433MHz transmitter), a switch to indicate if the timer is on or not and finally a slider to control what the target temperature should be when the heating is active.
Top right is a history card showing the various temperature sensors around the house as well as the target temperature state of the heating over the past 24 hours.
The bottom two cards show the timer times for week days and weekends. I did consider making a full 7 day timer, but this ends up good enough and I couldn’t find a better way to represent a set of start + end times that would have allowed a clean interface display of a full week. The times control when the “Heating timer” control in the top left is switched on + off.
These 4 cards provide the ability to see the current state of the heating, and tweak it, ideally meaning there’s no need to hand edit config files during normal operation. Rough theory of operation is:
- If the timer is on and someone is at home, raise the target temperature to the value set in the temperature slider.
- If the timer turns off or everyone leaves the house, lower the target temperature to 5°C.
The core is a generic thermostat:
climate:
- platform: generic_thermostat
name: Heating
heater: switch.gas_boiler
target_sensor: sensor.living_room_temperature
min_temp: 5
max_temp: 25
ac_mode: false
hot_tolerance: 0.5
cold_tolerance: 0.1
min_cycle_duration:
minutes: 5
keep_alive:
minutes: 30
initial_operation_mode: 'auto'
This is always active, and climate.set_temperature used to control what the target temperature is.
The temperature control slider is a simple input_number:
input_number:
heating_temperature:
name: Temperature
min: 5
max: 25
step: 0.5
icon: mdi:thermometer
The timer is where it gets complex. There are 8 input_datetime entries to deal with the different start/stop times. It seems like there should be an easier way, but this is what I have:
Heating start/stop time inputs
input_datetime:
weekday_morning_start:
name: Week day morning start
has_time: true
has_date: false
weekday_morning_stop:
name: Week day morning stop
has_time: true
has_date: false
weekend_morning_start:
name: Weekend morning start
has_time: true
has_date: false
weekend_morning_stop:
name: Weekend morning stop
has_time: true
has_date: false
weekday_evening_start:
name: Week day evening start
has_time: true
has_date: false
weekday_evening_stop:
name: Week day evening stop
has_time: true
has_date: false
weekend_evening_start:
name: Weekend evening start
has_time: true
has_date: false
weekend_evening_stop:
name: Weekend evening stop
has_time: true
has_date: false
For the automations I also needed to add a time & date sensor:
sensor:
- platform: time_date
display_options:
- 'time'
And finally the output input_boolean to represent if the timer is active or not:
input_boolean:
heating_timer:
name: Heating timer
icon: mdi:toggle-switch
These get tied together with a bunch of automations:
Automations for heating timer
automation:
- id: heating_morning_on_wd
alias: Turn heating on (weekday mornings)
trigger:
platform: template
value_template: "{{ states('sensor.time') == (states.input_datetime.weekday_morning_start.attributes.timestamp | int | timestamp_custom('%H:%M', False)) }}"
condition:
condition: time
weekday:
- mon
- tue
- wed
- thu
- fri
action:
service: input_boolean.turn_on
data_template:
entity_id: input_boolean.heating_timer
- id: heating_morning_off_wd
alias: Turn heating off (weekday mornings)
trigger:
platform: template
value_template: "{{ states('sensor.time') == (states.input_datetime.weekday_morning_stop.attributes.timestamp | int | timestamp_custom('%H:%M', False)) }}"
condition:
condition: time
weekday:
- mon
- tue
- wed
- thu
- fri
action:
service: input_boolean.turn_off
data_template:
entity_id: input_boolean.heating_timer
- id: heating_evening_on_wd
alias: Turn heating on (weekday evenings)
trigger:
platform: template
value_template: "{{ states('sensor.time') == (states.input_datetime.weekday_evening_start.attributes.timestamp | int | timestamp_custom('%H:%M', False)) }}"
condition:
condition: time
weekday:
- mon
- tue
- wed
- thu
- fri
action:
service: input_boolean.turn_on
data_template:
entity_id: input_boolean.heating_timer
- id: heating_evening_off_wd
alias: Turn heating off (weekday evenings)
trigger:
platform: template
value_template: "{{ states('sensor.time') == (states.input_datetime.weekday_evening_stop.attributes.timestamp | int | timestamp_custom('%H:%M', False)) }}"
condition:
condition: time
weekday:
- mon
- tue
- wed
- thu
- fri
action:
service: input_boolean.turn_off
data_template:
entity_id: input_boolean.heating_timer
- id: heating_morning_on_we
alias: Turn heating on (weekend mornings)
trigger:
platform: template
value_template: "{{ states('sensor.time') == (states.input_datetime.weekend_morning_start.attributes.timestamp | int | timestamp_custom('%H:%M', False)) }}"
condition:
condition: time
weekday:
- sat
- sun
action:
service: input_boolean.turn_on
data_template:
entity_id: input_boolean.heating_timer
- id: heating_morning_off_we
alias: Turn heating off (weekend mornings)
trigger:
platform: template
value_template: "{{ states('sensor.time') == (states.input_datetime.weekend_morning_stop.attributes.timestamp | int | timestamp_custom('%H:%M', False)) }}"
condition:
condition: time
weekday:
- sat
- sun
action:
service: input_boolean.turn_off
data_template:
entity_id: input_boolean.heating_timer
- id: heating_evening_on_we
alias: Turn heating on (weekend evenings)
trigger:
platform: template
value_template: "{{ states('sensor.time') == (states.input_datetime.weekend_evening_start.attributes.timestamp | int | timestamp_custom('%H:%M', False)) }}"
condition:
- condition: time
weekday:
- sat
- sun
action:
service: input_boolean.turn_on
data_template:
entity_id: input_boolean.heating_timer
- id: heating_evening_off_we
alias: Turn heating off (weekend evenings)
trigger:
platform: template
value_template: "{{ states('sensor.time') == (states.input_datetime.weekend_evening_stop.attributes.timestamp | int | timestamp_custom('%H:%M', False)) }}"
condition:
condition: time
weekday:
- sat
- sun
action:
service: input_boolean.turn_off
data_template:
entity_id: input_boolean.heating_timer
The timer boolean switch and the group.all_devices presence information are then tied together to raise/lower the target temperature as appropriate. I’ve used 4 automations for this - one triggered for timer on, one for timer off, one for someone arriving at home, one for everyone leaving. Again, there might be a better way, but this does what I need:
Automations to raise/lower target temperature
automation:
- id: heating_timer_on
alias: Turn heating on based on timer
trigger:
platform: state
entity_id: input_boolean.heating_timer
to: 'on'
condition:
condition: state
entity_id: group.all_devices
state: 'home'
action:
service: climate.set_temperature
data_template:
entity_id: climate.heating
temperature: "{{ states('input_number.heating_temperature') }}"
- id: heating_timer_off
alias: Turn heating off based on timer
trigger:
platform: state
entity_id: input_boolean.heating_timer
to: 'off'
action:
service: climate.set_temperature
data:
entity_id: climate.heating
temperature: 5
- id: heating_on_when_get_home
alias: Turn heating on on arrival if timer on
trigger:
platform: state
entity_id: group.all_devices
from: "not_home"
to: "home"
condition:
condition: state
entity_id: input_boolean.heating_timer
state: 'on'
action:
service: climate.set_temperature
data_template:
entity_id: climate.heating
temperature: "{{ states('input_number.heating_temperature') }}"
- id: heating_off_when_leave_home
alias: Turn heating off when we leave home
trigger:
platform: state
entity_id: group.all_devices
from: "home"
to: "not_home"
action:
service: climate.set_temperature
data:
entity_id: climate.heating
temperature: 5
Finally there’s the UI configuration, which I’ve done using Lovelace. The use of ‘:’ as the name for the climate.heating element is a kludge - I haven’t figured out yet how to name each individual data entry it adds to the history graph. I’m not particularly fond of the input method for controlling times - something closer to the Android analog clock with digits at the top would be nicer, but I’m not a UI guy and this works well enough.
Lovelace configuration for heating controls
views:
- title: Heating
cards:
- type: entities
title: Controls
show_header_toggle: false
entities:
- climate.heating
- switch.gas_boiler
- input_boolean.heating_timer
- input_number.heating_temperature
- type: history-graph
title: Temperatures
entities:
- entity: sensor.kitchen_temperature
name: Kitchen
- entity: sensor.living_room_temperature
name: Living Room
- entity: sensor.master_bedroom_temperature
name: Master Bedroom
- entity: sensor.outside
name: Outside
- entity: sensor.study_temperature
name: Study
- entity: climate.heating
name: ":"
- type: entities
title: Week day Timer
entities:
- input_datetime.weekday_morning_start
- input_datetime.weekday_morning_stop
- input_datetime.weekday_evening_start
- input_datetime.weekday_evening_stop
- type: entities
title: Weekend Timer
entities:
- input_datetime.weekend_morning_start
- input_datetime.weekend_morning_stop
- input_datetime.weekend_evening_start
- input_datetime.weekend_evening_stop
Using ARP via netlink to detect presence
If you remember my first post about home automation I mentioned a desire to use some sort of presence detection as part of deciding when to turn the heat on. Home Assistant has a wide selection of presence detection modules available, but the easy ones didn’t seem like the right solutions. I don’t want something that has to run on my phone to say where I am, but using the phone as the proxy for presence seemed reasonable. It connects to the wifi when at home, so watching for that involves no overhead on the phone and should be reliable (as long as I haven’t let my phone run down). I run OpenWRT on my main house router and there are a number of solutions which work by scraping the web interface. openwrt_hass_devicetracker is a bit better but it watches the hostapd logs and my wifi is actually handled by some UniFis.
So how to do it more efficiently? Learn how to watch for ARP requests via Netlink! That way I could have something sitting idle and only doing any work when it sees a new event, that could be small enough to run directly on the router. I could then tie it together with the Mosquitto client libraries and announce presence via MQTT, tying it into Home Assistant with the MQTT Device Tracker.
I’m going to go into a bit more detail about the Netlink side of things, because I found it hard to find simple documentation and ended up reading kernel source code to figure out what I wanted. If you’re not interested in that you can find my mqtt-arp (I suck at naming simple things) tool locally or on GitHub. It ends up as an 8k binary for my MIPS based OpenWRT box and just needs fed a list of MAC addresses to watch for and details of the MQTT server. When it sees a device it cares about make an ARP request it reports the presence for that device as “home” (configurable), rate limiting it to at most once every 2 minutes. Once it hasn’t seen anything from the device for 10 minutes it declares the location to be unknown. I have found Samsung phones are a little prone to disconnecting from the wifi when not in use so you might need to lengthen the timeout if all you have are Samsung devices.
Home Assistant configuration is easy:
device_tracker:
- platform: mqtt
devices:
noodles: 'location/by-mac/0C:11:22:33:44:55'
helen: 'location/by-mac/4C:11:22:33:44:55'
On to the Netlink stuff…
Firstly, you can watch the netlink messages we’re interested in using iproute2 - just run ip monitor. Works as an unpriviledged user which is nice. This happens via an AF_NETLINK routing socket (rtnetlink(7)):
int sock;
sock = socket(AF_NETLINK, SOCK_RAW, NETLINK_ROUTE);
We then want to indicate we’re listening for neighbour events:
struct sockaddr_nl group_addr;
bzero(&group_addr, sizeof(group_addr));
group_addr.nl_family = AF_NETLINK;
group_addr.nl_pid = getpid();
group_addr.nl_groups = RTMGRP_NEIGH;
bind(sock, (struct sockaddr *) &group_addr, sizeof(group_addr));
At this point we’re good to go and can wait for an event message:
received = recv(sock, buf, sizeof(buf), 0);
This will be a struct nlmsghdr message and the nlmsg_type field will provide details of what type. In particular I look for RTM_NEWNEIGH, indicating a new neighbour has been seen. This is of type struct ndmsg and immediately follows the struct nlmsghdr in the received message. That has details of the address family type (IPv6 vs IPv4), the state and various flags (such as whether it’s NUD_REACHABLE indicating presence). The only slightly tricky bit comes in working out the MAC address, which is one of potentially several struct nlattr attributes which follow the struct ndmsg. In particular I’m interested in an nla_type of NDA_LLADDR, in which case the attribute data is the MAC address. The main_loop function in mqtt-arp.c shows this - it’s fairly simple stuff, and works nicely. It was just figuring out the relationship between it all and the exact messages I cared about that took me a little time to track down.
PSA: the.earth.li ceasing Debian mirror service
This is a public service announcement that the.earth.li (the machine that hosts this blog) will cease service as a Debian mirror on 1st February 2019 at the latest.
It has already been removed from the official list of Debian mirrors. Please update your sources.list to point to an alternative sooner rather than later.
The removal has been driven by a number of factors:
- This mirror was originally setup when I was running Black Cat Networks, and a local mirror was generally useful to us. It’s 11+ years since Black Cat was sold, and 7+ since it moved away from that network.
- the.earth.li currently lives with Bytemark, who already have an official secondary mirror. It does not add any useful resilience to the mirror network.
- For a long time I’ve been unable to mirror all release architectures due to disk space limitations; I think such mirrors are of limited usefulness unless located in locations with dubious connectivity to alternative full mirrors.
- Bytemark have been acquired by IOMart and I’m uncertain as to whether my machine will remain there long term - the acquisition announcement focuses on their cloud service rather than mentioning physical server provision. Disk space requirements are one of my major costs and the Debian mirror makes up ⅔ of my current disk usage. Dropping it will make moving host easier for me, should it prove necessary.
I can’t find an exact record of when I started running a mirror, but it was certainly before April 2005. 13 years doesn’t seem like a bad length of time to have been providing the service. Personally I’ve moved to deb.debian.org but if the network location of the is the reason you chose it then mirror.bytemark.co.uk should be a good option.
Controlling the Energenie 433MHz mains switch with an ATTiny

My first attempt at home automation involved a dark internal staircase in my flat, a set of white LED fairy lights and a plan to make them switch on when I was at home and the sun had set. I purchased a set of Energenie sockets and the associated Pi-Mote to control the lights and looked at what my control options were. Nothing really stood out so I started writing some Python that would watch for my phone being connected to the wifi, look at whether the sun had set and send the appropriate commands. Unfortunately the range on the Energenie sockets and/or the Pi-mote ended up too poor to work from where the Pi was located to the socket out in the hallway. I tried soldered an antenna onto the Pi-mote, but it still ended up too unreliable. Subsequently something happened to the Pi-mote and it stopped working entirely. The sockets were still working ok, and for a while I made some use of them with the provided remote control, but until recently they had been sitting in a box for a couple of years.
With my more recent, more successful foray into automation I decided to try and revive the Energenie sockets as part of my setup. Poking the Pi-mote confirmed it was dead - trying to drive it manually rather than with the Pi resulted in no output signal. However I’d purchased a cheap 433MHz receiver/transmitter pair (MX-RM-5V + FS1000A) - very cheap and nasty, but easy to poke. I found a good writeup of the Energenie protocol and how to drive it via FT232R bitbanging and Glen Pitt-Pladdy also had some details. Using PulseView and my cheap Cypress FX2 analyser hooked up to the MX-RM-5V I was able to capture the 20 digit code from my remote control.
All that remained was to try and transmit the code + appropriate power on/off commands for each of my 4 sockets. I still have spare Digispark clones, so that seemed like a good starting point. My initial first steps with ATTinys involved a relay board which was available with up to 8 ports. It made sense to try and emulate a 4 port relay board on a device that would actually send out the appropriate 433MHz signals. In addition the relay boards have 5 digits of configurable serial number - perfect for a 20 bit ID code! I took my existing code and fixed it up so that instead of setting/clearing the appropriate output pin bit it wiggled a single pin, connected to the FS1000A, in the appropriate manner for the Energenie. It took a little bit of twiddling, and I had to solder an antenna onto the FS1000A to get better range, but I’ve ended up with 2 sockets in the same room as the Digispark/transmitter dongle, and another in the next room on just the other side of the wall.
For initial testing I used Darryl Bond’s usbrelay, which is handy because it also supports setting the serial number, so I didn’t have to hard code anything into my image. Ultimately I wrote my own code to control the device in Python, and of course hooked it into my MQTT setup. This tied it into Home Assistant like any other set of MQTT lights, and ultimately into Alexa.
Ultimately the SonOff is better technically - the use of an ESP8266 directly on the device means you get a direct secure MQTT/TLS connection rather than an easily sniffable/clonable 433MHz signal, plus it’s bidirectional so you can be sure the device is in the state you think it is. However I had these switches lying around and a spare Digispark so the only expenditure was a couple of quid for the transmitter/receiver pair. Plus it was fun to figure it out and end up with a useful result, and some of the information learned will be useful for controlling my heating (which is on a 433MHz thermostat).
The code is locally and on GitHub in case it’s of use/interest to anyone else.
DebConf18 writeup
I’m just back from DebConf18, which was held in Hsinchu, Taiwan. I went without any real concrete plans about what I wanted to work on - I had some options if I found myself at a loose end, but no preconceptions about what would pan out. In the end I felt I had a very productive conference and I did bits on all of the following:
- Worked on trying to fix my corrupted Lenovo Ideacentre Stick 300 BIOS (testing of current attempt has been waiting until I’m back home and have access to the device again, so hopefully within the next few days)
- NMUed sdcc to fix FTBFS with GCC 8
- Prepared Pulseview upload to fix FTBFS with GCC 8, upload stalled on libsigc++2.0 (Bug#897895)
- Caught up with Gunnar re keyring stuff
- Convinced John Sullivan to come and help out keyring-maint
- New Member / Front Desk conversations
- Worked on gcc toolchain packages for ESP8266 (xtensa-lx106) (Bug#868895). Not sure if these are useful enough to others to upload or not, but so far I’ve moved from 4.8.5 to 7.3 and things seem happy.
- Worked on porting latest newlib to xtensa with help from Keith Packard (in particular his nano variant with much smaller stdio code)
- Helped present the state of Debian + the GDPR
- Sat on the New Members BoF panel
- Went to a whole bunch of interesting talks + BoFs.
- Put faces to a number of names, as well as doing the usual catchup with the familiar faces.
I managed to catch the DebConf bug towards the end of the conference, which was unfortunate - I had been eating the venue food at the start of the week and it would have been nice to explore the options in Hsinchu itself for dinner, but a dodgy tummy makes that an unwise idea. Thanks to Stuart Prescott I squeezed in a short daytrip to Taipei yesterday as my flight was in the evening and I was going to have to miss all the closing sessions anyway. So at least I didn’t completely avoid seeing some of Taiwan when I was there.
As usual thanks to all the organisers for their hard work, and looking forward to DebConf19 in Curitiba, Brazil!
subscribe via RSS