onak 0.6.5 released
I had intended that the next release of onak, my OpenPGP keyserver, would be 0.7.0, and include OpenPGP v6 support (RFC9580). However events conspired to make a 0.6.5 release a really good idea.
Firstly, I threw an LLM at the code base and asked it to review it. This isn’t intended to be a post about LLMs, but there’s a considerable amount of pressure at work to be “AI native”. I’m very much an “AI” sceptic, so I figured throwing it at a code base I know well might be an interesting exercise. It did find a bunch of embarrassing mistakes, but I don’t think there was anything earth shattering that a human reviewer wouldn’t have pulled me on. The problem is with a hobby project with a single user there’s no actual review of my work.
I also enabled GitHub’s security scanning. It mostly complained about format strings, and those were easy enough to fix up.
Next I threw AFLplusplus at the code. I’d previously tried American Fuzzy Lop, but not in some time. AFL++ found a whole bunch of places I should really have checked available buffer lengths and wasn’t doing so. It really is an incredibly easy tool to get up and running.
valgrind is also a tool I’ve used before, and rate highly. Thankfully it didn’t find anything in my testing this time.
Finally I threw a few more automated tests into the mix and discovered something has changed around dynamic linking such that the libonak symbols in the dynamic key database backends were using private copies, rather than the main binary. This caused problems with seeing the correct configuration settings in some instances.
All in all this release is not my proudest moment; a bunch of the issues fixed should never have made it to a release.
(Also, just to explicitly state it, all the actual code in this release was artisanly crafted by me, in vim. The only involvement of an LLM was for a review pass.)
Available locally or via GitHub.
0.6.5 - 27th June 2026
- Lots of fixes/improvements around length checking
- Added extra basic tests for maxpaths/sixdegrees/CGI
- Correctly end transactions in the stacked backend
- Ensure the file backend avoids stale key data on updates
- Fix decoding of v2/3 signature creation times
- Fix EdDSA signature parsing when r < 249 bits long
- Fix migration of bools from old to new config style
- Fix parsing of new config details for DB parameters
- Fix problems with linking + dynamic backends
- Fix RSA-SHA2-384 signature checking
- Fix sixdegrees parsing of keyids with high bit set
- Handle failures in maxpath more gracefully
- Make new style config path match old path
Free Software Activities for 2025
Given we’ve entered a new year it’s time for my annual recap of my Free Software activities for the previous calendar year. For previous years see 2019, 2020, 2021, 2022, 2023 + 2024.
Conferences
My first conference of the year was FOSDEM. I’d submitted a talk proposal about system attestation in production environments for the attestation devroom, but they had a lot of good submissions and mine was a bit more “this is how we do it” rather than “here’s some neat Free Software that does it”. I’m still trying to work out how to make some of the bits we do more open, but the problem is a lot of the neat stuff is about taking internal knowledge about what should be running and making sure that’s the case, and what you end up with if you abstract that is a toolkit that still needs a lot of work to get something useful.
I’d more luck at DebConf25 where I gave a talk (Don’t fear the TPM) trying to explain how TPMs could be useful in a Debian context. Naturally the comments section descended into a discussion about UEFI Secure Boot, which is a separate, if related, thing. DebConf also featured the usual catch up with fellow team members, hanging out with folk I hadn’t seen in ages, and generally feeling a bit more invigorated about Debian.
Other conferences I considered, but couldn’t justify, were All Systems Go! and the Linux Plumbers Conference. I’ve no doubt both would have had a bunch of interesting and relevant talks + discussions, but not enough this year.
I’m going to have to miss FOSDEM this year, due to travel later in the month, and I’m uncertain if I’m going to make DebConf (for a variety of reasons). That means I don’t have a Free Software conference planned for 2026. Ironically FOSSY moving away from Portland makes it a less appealing option (I have Portland friends it would be good to visit). Other than potential Debian MiniConfs, anything else European I should consider?
Debian
I continue to try and keep RetroArch in shape, with 1.22.2+dfsg-1 (and, shortly after, 1.22.2+dfsg-2 - git-buildpackage in trixie seems more strict about Build-Depends existing in the outside environment, and I keep forgetting I need Build-Depends-Arch and Build-Depends-Indep to be pretty much the same with a minimal Build-Depends that just has enough for the clean target) getting uploaded in December, and 1.20.0+dfsg-1, 1.20+dfsg-2 + 1.20+dfsg-3 all being uploaded earlier in the year. retroarch-assets had 1.20.0+dfsg-1 uploaded back in April. I need to find some time to get 1.22.0 packaged. libretro-snes9x got updated to 1.63+dfsg-1.
sdcc saw 4.5.0+dfsg-1, 4.5.0+dfsg-2, 4.5.0+dfsg-3 (I love major GCC upgrades) and 4.5.0-dfsg-4 uploads. There’s an outstanding bug around a LaTeX error building the manual, but this turns out to be a bug in the 2.5 RC for LyX. Huge credit to Tobias Quathamer for engaging with this, and Pavel Sanda + Jürgen Spitzmüller from the LyX upstream for figuring out the issue + a fix.
Pulseview saw 0.4.2-4 uploaded to fix issues with the GCC 15 + CMake upgrades. I should probably chase the sigrok upstream about new releases; I think there are a bunch of devices that have gained support in git without seeing a tagged release yet.
I did an Electronics Team upload for gputils 1.5.2-2 to fix compilation with GCC 15.
While I don’t do a lot with storage devices these days if I can help it I still pay a little bit of attention to sg3-utils. That resulted in 1.48-2 and 1.48-3 uploads in 2025.
libcli got a 1.10.7-3 upload to deal with the libcrypt-dev split out.
Finally I got more up-to-date versions of libtorrent (0.15.7-1) and rtorrent (also 0.15.7-1) uploaded to experimental. There’s a ppc64el build failure in libtorrent, but having asked on debian-powerpc this looks like a flaky test/code and I should probably go ahead and upload to unstable.
I sponsored some uploads for Michel Lind - the initial uploads of plymouth-theme-hot-dog, and the separated out pykdumpfile package.
Recognising the fact I wasn’t contributing in a useful fashion to the Data Protection Team I set about trying to resign in an orderly fashion - see Andreas’ call for volunteers that went out in the last week. Shout out to Enrico for pointing out in the past that we should gracefully step down from things we’re not actually managing to do, to avoid the perception it’s all fine and no one else needs to step up. Took me too long to act on it.
The Debian keyring team continues to operate smoothly, maintaining our monthly release cadence with a 3 month rotation ensuring all team members stay familiar with the process, and ensure their setups are still operational (especially important after Debian releases). I handled the 2025.03.23, 2025.06.24, 2025.06.27, 2025.09.18, 2025.12.08 + 2025.12.26 pushes.
Linux
TPM related fixes were the theme of my kernel contributions in 2025, all within a work context. Some were just cleanups, but several fixed real issues that were causing us issues. I’ve also tried to be more proactive about reviewing diffs in the TPM subsystem; it feels like a useful way to contribute, as well as making me more actively pay attention to what’s going on there.
Personal projects
I did some work on onak, my OpenPGP keyserver. That resulted in a 0.6.4 release, mainly driven by fixes for building with more recent CMake + GCC versions in Debian. I’ve got a set of changes that should add RFC9580 (v6) support, but there’s not a lot of test keys out there at present for making sure I’m handling things properly. Equally there’s a plan to remove Berkeley DB from Debian, which I’m completely down with, but that means I need a new primary backend. I’ve got a draft of LMDB support to replace that, but I need to go back and confirm I’ve got all the important bits implemented before publishing it and committing to a DB layout. I’d also like to add sqlite support as an option, but that needs some thought about trying to take proper advantage of its features, rather than just treating it as a key-value store.
(I know everyone likes to hate on OpenPGP these days, but I continue to be interested by the whole web-of-trust piece of it, which nothing else I’m aware of offers.)
That about wraps up 2025. Nothing particularly earth shaking in there, more a case of continuing to tread water on the various things I’m involved. I highly doubt 2026 will be much different, but I think that’s ok. I scratch my own itches, and if that helps out other folk too then that’s lovely, but not the primary goal.
NanoKVM: I like it
I bought a NanoKVM. I’d heard some of the stories about how terrible it was beforehand, and some I didn’t learn about until afterwards, but at £52, including VAT + P&P, that seemed like an excellent bargain for something I was planning to use in my home network environment.
Let’s cover the bad press first. apalrd did a video, entitled NanoKVM: The S stands for Security (Armen Barsegyan has a write up recommending a PiKVM instead that lists the objections raised in the video). Matej Kovačič wrote an article about the hidden microphone on a Chinese NanoKVM. Various other places have picked up both of these and still seem to be running with them, 10 months later.
Next, let me explain where I’m coming from here. I have over 2 decades of experience with terrible out-of-band access devices. I still wince when I think of the Sun Opteron servers that shipped with an iLOM that needed a 32-bit Windows browser in order to access it (IIRC some 32 bit binary JNI blob). It was a 64 bit x86 server from a company who, at the time, still had a major non-Windows OS. Sheesh. I do not assume these devices are fit for exposure to the public internet, even if they come from “reputable” vendors. Add into that the fact the NanoKVM is very much based on a development board (the LicheeRV Nano), and I felt I knew what I was getting into here.
And, as a TL;DR, I am perfectly happy with my purchase. Sipeed have actually dealt with a bunch of apalrd’s concerns (GitHub ticket), which I consider to be an impressive level of support for this price point. Equally the microphone is explained by the fact this is a £52 device based on a development board. You’re giving it USB + HDMI access to a host on your network, if you’re worried about the microphone then you’re concentrating on the wrong bit here.
I started out by hooking the NanoKVM up to my Raspberry Pi classic, which I use as a serial console / network boot tool for working on random bits of hardware. That meant the NanoKVM had no access to the outside world (the Pi is not configured to route, or NAT, for the test network interface), and I could observe what went on. As it happens you can do an SSH port forward of port 80 with this sort of setup and it all works fine - no need for the NanoKVM to have any external access, and it copes happily with being accessed as http://localhost:8000/ (though you do need to choose MJPEG as the video mode, more forwarding or enabling HTTPS is needed for an H.264 WebRTC session).
IPv6 is enabled in the kernel. My test setup doesn’t have a router advertisements configured, but I could connect to the web application over the v6 link-local address that came up automatically.
My device reports:
Image version: v1.4.1
Application version: 2.2.9
That’s recent, but the GitHub releases page has 2.3.0 listed as more recent.
Out of the box it’s listening on TCP port 80. SSH is not running, but there’s a toggle to turn it on and the web interface offers a web based shell (with no extra authentication over the normal login). On first use I was asked to set a username + password. Default access, as you’d expect from port 80, is HTTP, but there’s a toggle to enable HTTPS. It generates a self signed certificate - for me it had the CN localhost but that might have been due to my use of port forwarding. Enabling HTTPS does not disable HTTP, but HTTP just redirects to the HTTPS URL.
As others have discussed it does a bunch of DNS lookups, primarily for NTP servers but also for cdn.sipeed.com. The DNS servers are hard coded:
~ # cat /etc/resolv.conf
nameserver 192.168.0.1
nameserver 8.8.4.4
nameserver 8.8.8.8
nameserver 114.114.114.114
nameserver 119.29.29.29
nameserver 223.5.5.5
This is actually restored on boot from /boot/resolv.conf, so if you want changes to persist you can just edit that file. NTP is configured with a standard set of pool.ntp.org services in /etc/ntp.conf (this does not get restored on reboot, so can just be edited in place). I had dnsmasq on the Pi setup to hand out DNS + NTP servers, but both were ignored (though actually udhcpc does write the DNS details to /etc/resolv.conf.dhcp).
My assumption is the lookup to cdn.sipeed.com is for firmware updates (as I bought the NanoKVM cube it came fully installed, so no need for a .so download to make things work); when working DNS was provided I witness attempts to connect to HTTPS. I’ve not bothered digging further into this. I did go grab the latest.zip being served from the URL, which turned out to be v2.2.9, matching what I have installed, not the latest on GitHub.
I note there’s an iptables setup (with nftables underneath) that’s not fully realised - it seems to be trying to allow inbound HTTP + WebRTC, as well as outbound SSH, but everything is default accept so none of it gets hit. Setting up a default deny outbound and tweaking a little should provide a bit more reassurance it’s not going to try and connect out somewhere it shouldn’t.
It looks like updates focus solely on the KVM application, so I wanted to take a look at the underlying OS. This is buildroot based:
~ # cat /etc/os-release
NAME=Buildroot
VERSION=-g98d17d2c0-dirty
ID=buildroot
VERSION_ID=2023.11.2
PRETTY_NAME="Buildroot 2023.11.2"
The kernel reports itself as 5.10.4-tag-. Somewhat ancient, but actually an LTS kernel. Except we’re now up to 5.10.247, so it obviously hasn’t been updated in some time.
TBH, this is what I expect (and fear) from embedded devices. They end up with some ancient base OS revision and a kernel with a bunch of hacks that mean it’s not easily updated. I get that the margins on this stuff are tiny, but I do wish folk would spend more time upstreaming. Or at least updating to the latest LTS point release for their kernel.
The SSH client/daemon is full-fat OpenSSH:
~ # sshd -V
OpenSSH_9.6p1, OpenSSL 3.1.4 24 Oct 2023
There are a number of CVEs fixed in later OpenSSL 3.1 versions, though at present nothing that looks too concerning from the server side. Yes, the image has tcpdump + aircrack installed. I’m a little surprised at aircrack (the device has no WiFi and even though I know there’s a variant that does, it’s not a standard debug tool the way tcpdump is), but there’s a copy of GNU Chess in there too, so it’s obvious this is just a kitchen-sink image. FWIW it looks like the buildroot config is here.
Sadly the UART that I believe the bootloader/kernel are talking to is not exposed externally - the UART pin headers are for UART1 + 2, and I’d have to open up the device to get to UART0. I’ve not yet done this (but doing so would also allow access to the SD card, which would make trying to compile + test my own kernel easier).
In terms of actual functionality it did what I’d expect. 1080p HDMI capture was fine. I’d have gone for a lower resolution, but I think that would have required tweaking on the client side. It looks like the 2.3.0 release allows EDID tweaking, so I might have to investigate that. The keyboard defaults to a US layout, which caused some problems with the | symbol until I reconfigured the target machine not to expect a GB layout.
There’s also the potential to share out images via USB. I copied a Debian trixie netinst image to /data on the NanoKVM and was able to select it in the web interface and have it appear on the target machine easily. There’s also the option to fetch direct from a URL in the web interface, but I was still testing without routable network access, so didn’t try that. There’s plenty of room for images:
~ # df -h
Filesystem Size Used Available Use% Mounted on
/dev/mmcblk0p2 7.6G 823.3M 6.4G 11% /
devtmpfs 77.7M 0 77.7M 0% /dev
tmpfs 79.0M 0 79.0M 0% /dev/shm
tmpfs 79.0M 30.2M 48.8M 38% /tmp
tmpfs 79.0M 124.0K 78.9M 0% /run
/dev/mmcblk0p1 16.0M 11.5M 4.5M 72% /boot
/dev/mmcblk0p3 22.2G 160.0K 22.2G 0% /data
The NanoKVM also appears as an RNDIS USB network device, with udhcpd running on the interface. IP forwarding is not enabled, and there’s no masquerading rules setup, so this doesn’t give the target host access to the “management” LAN by default. I guess it could be useful for copying things over to the target host, as a more flexible approach than a virtual disk image.
One thing to note is this makes for a bunch of devices over the composite USB interface. There are 3 HID devices (keyboard, absolute mouse, relative mouse), the RNDIS interface, and the USB mass storage. I had a few occasions where the keyboard input got stuck after I’d been playing about with big data copies over the network and using the USB mass storage emulation. There is a HID-only mode (no network/mass storage) to try and help with this, and a restart of the NanoKVM generally brought things back, but something to watch out for. Again I see that the 2.3.0 application update mentions resetting the USB hardware on a HID reset, which might well help.
As I stated at the start, I’m happy with this purchase. Would I leave it exposed to the internet without suitable firewalling? No, but then I wouldn’t do so for any KVM. I wanted a lightweight KVM suitable for use in my home network, something unlikely to see heavy use but that would save me hooking up an actual monitor + keyboard when things were misbehaving. So far everything I’ve seen says I’ve got my money’s worth from it.
21 years of blogging
21 years ago today I wrote my first blog post. Did I think I’d still be writing all this time later? I’ve no idea to be honest. I’ve always had the impression my readership is small, and people who mostly know me in some manner, and I post to let them know what I’m up to in more detail than snippets of IRC conversation can capture. Or I write to make notes for myself (I frequently refer back to things I’ve documented here). I write less about my personal life than I used to, but I still occasionally feel the need to mark some event.
From a software PoV I started out with Blosxom, migrated to MovableType in 2008, ditched that, when the Open Source variant disappeared, for Jekyll in 2015 (when I also started putting it all in git). And have stuck there since. The static generator format works well for me, and I outsource comments to Disqus - I don’t get a lot, I can’t be bothered with the effort of trying to protect against spammers, and folk who don’t want to use it can easily email or poke me on the Fediverse. If I ever feel the need to move from Jekyll I’ll probably take a look at Hugo, but thankfully at present there’s no push factor to switch.
It’s interesting to look at my writing patterns over time. I obviously started keen, and peaked with 81 posts in 2006 (I’ve no idea how on earth that happened), while 2013 had only 2. Generally I write less when I’m busy, or stressed, or unhappy, so it’s kinda interesting to see how that lines up with various life events.
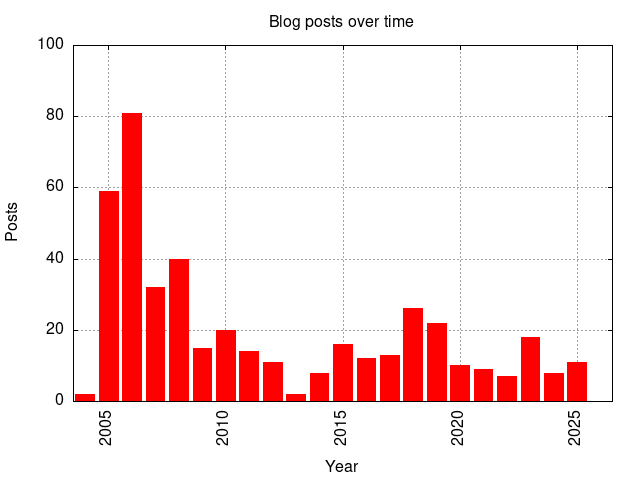
During that period I’ve lived in 10 different places (well, 10 different houses/flats, I think it’s only 6 different towns/cities), on 2 different continents, working at 6 different employers, as well as a period where I was doing my Masters in law. I’ve travelled around the world, made new friends, lost contact with folk, started a family. In short, I have lived, even if lots of it hasn’t made it to these pages.
At this point, do I see myself stopping? No, not really. I plan to still be around, like Flameeyes, to the end. Even if my posts are unlikely to hit the frequency from back when I started out.
onak 0.6.4 released
A bit delayed in terms of an announcement, but last month I tagged a new version of onak, my OpenPGP compatible keyserver. It’s been 2 years since the last release, and this is largely a bunch of minor fixes to make compilation under Debian trixie with more recent CMake + GCC versions happy.
OpenPGP v6 support, RFC9580, hasn’t made it. I’ve got a branch which adds it, but a lack of keys to do any proper testing with, and no X448 support implemented, mean I’m not ready to include it in a release yet. The plan is that’ll land for 0.7.0 (along with some backend work), but no idea when that might be.
Available locally or via GitHub.
0.6.4 - 7th September 2025
- Fix building with CMake 4.0
- Fixes for building with GCC 15
- Rename keyd(ctl) to onak-keyd(ctl)
subscribe via RSS