Actually switching something with the SonOff
Getting a working MQTT temperature monitoring setup is neat, but not really what we think of when someone talks about home automation. For that we need some element of control. There are various intelligent light bulb systems out there that are obvious candidates, but I decided I wanted the more simple approach of switching on and off an existing lamp. I ended up buying a pair of Sonoff Basic devices; I’d rather not get into trying to safely switch mains voltages myself. As well as being cheap the Sonoff is based upon an ESP8266, which I already had some experience in hacking around with (I have a long running project to build a clock I’ll eventually finish and post about). Even better, the Sonoff-Tasmota project exists, providing an alternative firmware that has some support for MQTT/TLS. Perfect for my needs!
There’s an experimental OTA upgrade approach to getting a new firmware on the Sonoff, but I went the traditional route of soldering a serial header onto the board and flashing using esptool. Additionally none of the precompiled images have MQTT/TLS enabled, so I needed to build the image myself. Both of these turned out to be the right move, because using the latest release (v5.13.1 at the time) I hit problems with the device rebooting as soon as it got connected to the MQTT broker. The serial console allowed me to see the reboot messages, and as I’d built the image myself it was easy to tweak things in the hope of improving matters. It seems the problem is related to the memory consumption that enabling TLS requires. I went back a few releases until I hit on one that works, with everything else disabled. I also had to nail the Espressif Arduino library version to an earlier one to get a reliable wifi connection - using the latest worked fine when the device was power via USB from my laptop, but not once I hooked it up to the mains.
Once the image is installed on the device (just the normal ESP8266 esptool write_flash 0 sonoff-image.bin approach), start mosquitto_sub up somewhere. Plug the Sonoff in (you CANNOT have the Sonoff plugged into the mains while connected to the serial console, because it’s not fully isolated), and you should see something like the following:
$ mosquitto_sub -h mqtt-host -p 8883 --capath /etc/ssl/certs/ -v -t '#' -u user1 -P foo
tele/sonoff/LWT Online
cmnd/sonoff/POWER (null)
tele/sonoff/INFO1 {"Module":"Sonoff Basic","Version":"5.10.0","FallbackTopic":"DVES_123456","GroupTopic":"sonoffs"}
tele/sonoff/INFO3 {"RestartReason":"Power on"}
stat/sonoff/RESULT {"POWER":"OFF"}
stat/sonoff/POWER OFF
tele/sonoff/STATE {"Time":"2018-05-25T10:09:06","Uptime":0,"Vcc":3.176,"POWER":"OFF","Wifi":{"AP":1,"SSId":"My SSID Is Here","RSSI":100,"APMac":"AA:BB:CC:12:34:56"}}
Each of the Sonoff devices will want a different topic rather than the generic ‘sonoff’, and this can be set via MQTT:
$ mosquitto_pub -h mqtt.o362.us -p 8883 --capath /etc/ssl/certs/ -t 'cmnd/sonoff/topic' -m 'sonoff-snug' -u user1 -P foo
The device will provide details of the switchover via MQTT:
cmnd/sonoff/topic sonoff-snug
tele/sonoff/LWT (null)
stat/sonoff-snug/RESULT {"Topic":"sonoff-snug"}
tele/sonoff-snug/LWT Online
cmnd/sonoff-snug/POWER (null)
tele/sonoff-snug/INFO1 {"Module":"Sonoff Basic","Version":"5.10.0","FallbackTopic":"DVES_123456","GroupTopic":"sonoffs"}
tele/sonoff-snug/INFO3 {"RestartReason":"Software/System restart"}
stat/sonoff-snug/RESULT {"POWER":"OFF"}
stat/sonoff-snug/POWER OFF
tele/sonoff-snug/STATE {"Time":"2018-05-25T10:16:29","Uptime":0,"Vcc":3.103,"POWER":"OFF","Wifi":{"AP":1,"SSId":"My SSID Is Here","RSSI":76,"APMac":"AA:BB:CC:12:34:56"}}
Controlling the device is a matter of sending commands to the cmd/sonoff-snug/power topic - 0 for off, 1 for on. All of the available commands are listed on the Sonoff-Tasmota wiki.
At this point I have a wifi connected mains switch, controllable over MQTT via my internal MQTT broker.
(If you want to build your own Sonoff Tasmota image it’s actually not too bad; the build system is Ardunio style on top of PlatformIO. That means downloading a bunch of bits before you can actually build, but the core is Python based so it can be done as a normal user within a virtualenv. Here’s what I did:
# Make a directory to work in and change to it
mkdir sonoff-ws
cd sonoff-ws
# Build a virtual Python environment and activate it
virtualenv platformio
source platformio/bin/activate
# Install PlatformIO core
pip install -U platformio
# Clone Sonoff Tasmota tree
git clone https://github.com/arendst/Sonoff-Tasmota.git
cd Sonoff-Tasmota
# Checkout known to work release
git checkout v5.10.0
# Only build the sonoff firmware, not all the language variants
sed -i 's/;env_default = sonoff$/env_default = sonoff/' platformio.ini
# Force older version of espressif to get more reliable wifi
sed -i 's/platform = espressif8266$/&@1.5.0/' platformio.ini
# Edit the configuration to taste; essentially comment out all the USE_*
# defines and enable USE_MQTT_TLS
vim sonoff/user_config.h
# Actually build. Downloads a bunch of deps the first time.
platformio run
I’ve put my Sonoff-Tasmota user_config.h up in case it’s of help when trying to get up and going. At some point I need to try the latest version and see if I can disable enough to make it happy with MQTT/TLS, but for now I have an image that does what I need.)
Home Automation: Graphing MQTT sensor data
So I’ve setup a MQTT broker and I’m feeding it temperature data. How do I actually make use of this data? Turns out collectd has an MQTT plugin, so I went about setting it up to record temperature over time.
First problem was that although the plugin supports MQTT/TLS it doesn’t support it for subscriptions until 5.8, so I had to backport the fix to the 5.7.1 packages my main collectd host is running.
The other problem is that collectd is picky about the format it accepts for incoming data. The topic name should be of the format <host>/<plugin>-<plugin_instance>/<type>-<type_instance> and the data is <unixtime>:<value>. I modified my MQTT temperature reporter to publish to collectd/mqtt-host/mqtt/temperature-study, changed the publish line to include the timestamp:
publish.single(pub_topic, str(time.time()) + ':' + str(temp),
hostname=Broker, port=8883,
auth=auth, tls={})
and added a new collectd user to the Mosquitto configuration:
mosquitto_passwd -b /etc/mosquitto/mosquitto.users collectd collectdpass
And granted it read-only access to the collectd/ prefix via /etc/mosquitto/mosquitto.acl:
user collectd
topic read collectd/#
(I also created an mqtt-temp user with write access to that prefix for the Python script to connect to.)
Then, on the collectd host, I created /etc/collectd/collectd.conf.d/mqtt.conf containing:
LoadPlugin mqtt
<Plugin "mqtt">
<Subscribe "ha">
Host "mqtt-host"
Port "8883"
User "collectd"
Password "collectdpass"
CACert "/etc/ssl/certs/ca-certificates.crt"
Topic "collectd/#"
</Subscribe>
</Plugin>
I had some initial problems when I tried setting CACert to the Let’s Encrypt certificate; it actually wants to point to the “DST Root CA X3” certificate that signs that. Or using the full set of installed root certificates as I’ve done works too. Of course the errors you get back are just of the form:
collectd[8853]: mqtt plugin: mosquitto_loop failed: A TLS error occurred.
which is far from helpful. Once that was sorted collectd started happily receiving data via MQTT and producing graphs for me:
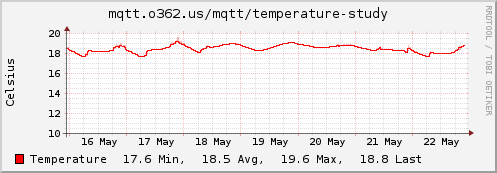
This is a pretty long winded way of ending up with some temperature graphs - I could have just graphed the temperature sensor using collectd on the Pi to send it to the monitoring host, but it has allowed a simple MQTT broker, publisher + subscriber setup with TLS and authentication to be constructed and confirmed as working.
Home Automation: Raspberry Pi as MQTT temperature sensor
After setting up an MQTT broker I needed some data to feed it. It made sense to start basic and gradually build up bits and pieces that would form a bigger home automation setup. As it happened I have an old Raspberry Pi B (original rev 1 [2 if you look at /proc/cpuinfo] with 256MB RAM) and some DS18B20 1-Wire temperature sensors lying around, so I decided to make a heavyweight temperature sensor (long term I’m hoping to do something with some ESP8266s).
There are plenty of guides out there about hooking up the DS18B20 to the Pi; Adafruit has a reasonable one. The short version is that GPIO4 can be easily configured to be a 1-Wire bus and you hook the DS18B20 up with a 4k7Ω resistor across the data + 3v3 power pins. An initial check can be performed by enabling the DT overlay on the fly:
sudo dtoverlay w1-gpio
Detection of 1-Wire devices is automatic so you should see an entry in dmesg looking like:
w1_master_driver w1_bus_master1: Attaching one wire slave 28.012345678abcd crc ef
You can then do
$ cat /sys/bus/w1/devices/28-*/w1_slave
1e 01 4b 46 7f ff 0c 10 18 : crc=18 YES
1e 01 4b 46 7f ff 0c 10 18 t=17875
Which shows a current temperature of 17.875°C in my sudy. Once that’s working (and you haven’t swapped GND and DATA like I did on the first go) you can make the Pi bootup with 1-Wire enabled by adding a dtoverlay=w1-gpio line to /boot/config.txt. The next step is to get that fed into the MQTT broker. A simple Python client seemed like the right approach. Debian has paho-mqtt but sadly not in a stable release. Thankfully the python3-paho-mqtt 1.3.1-1 package in testing installed just fine on the Raspbian stretch image my Pi is running. I dropped the following in /usr/locals/bin/mqtt-temp:
#!/usr/bin/python3
import glob
import time
import paho.mqtt.publish as publish
Broker = 'mqtt-host'
auth = {
'username': 'user2',
'password': 'bar',
}
pub_topic = 'test/temperature'
base_dir = '/sys/bus/w1/devices/'
device_folder = glob.glob(base_dir + '28-*')[0]
device_file = device_folder + '/w1_slave'
def read_temp():
valid = False
temp = 0
with open(device_file, 'r') as f:
for line in f:
if line.strip()[-3:] == 'YES':
valid = True
temp_pos = line.find(' t=')
if temp_pos != -1:
temp = float(line[temp_pos + 3:]) / 1000.0
if valid:
return temp
else:
return None
while True:
temp = read_temp()
if temp is not None:
publish.single(pub_topic, str(temp),
hostname=Broker, port=8883,
auth=auth, tls={})
time.sleep(60)
And finished it off with a systemd unit file - I know a lot of people complain about systemd, but it really does make it easy to just spin up a minimal service as a unique non-privileged user. The following went in /etc/systemd/system/mqtt-temp.service:
[Unit]
Description=MQTT Temperature sensor
After=network.target
[Service]
# Hack because Python can't cope with a DynamicUser with no HOME
Environment="HOME=/"
ExecStart=/usr/local/sbin/mqtt-temp
DynamicUser=yes
MemoryDenyWriteExecute=true
PrivateDevices=true
ProtectKernelTunables=true
ProtectControlGroups=true
RestrictRealtime=true
RestrictAddressFamilies=AF_INET AF_INET6 AF_UNIX
RestrictNamespaces=true
[Install]
WantedBy=multi-user.target
Start it up and enable for subsequent reboots:
systemctl start mqtt-temp
systemctl enable mqtt-temp
And then watch on my Debian test box as before:
$ mosquitto_sub -h mqtt-host -p 8883 --capath /etc/ssl/certs/ -v -t '#' -u user1 -P foo
test/temperature 17.875
test/temperature 17.937
Home Automation: Getting started with MQTT
I’ve been thinking about trying to sort out some home automation bits. I’ve moved from having a 7 day heating timer to a 24 hour timer and I’d forgotten how annoying that is at weekends. I’d like to monitor temperatures in various rooms and use that, along with presence detection, to be a bit more intelligent about turning the heat on. Equally I wouldn’t mind tying my Alexa in to do some voice control of lighting (eventually maybe even using DeepSpeech to keep everything local).
Before all of that I need to get the basics in place. This is the first in a series of posts about putting together the right building blocks to allow some useful level of home automation / central control. The first step is working out how to glue everything together. A few years back someone told me MQTT was the way forward for IoT applications, being more lightweight than a RESTful interface and thus better suited to small devices. At the time I wasn’t convinced, but it seems they were right and MQTT is one of the more popular ways of gluing things together.
I found the HiveMQ series on MQTT Essentials to be a pretty good intro; my main takeaway was that MQTT allows for a single message broker to enable clients to publish data and multiple subscribers to consume that data. TLS is supported for secure data transfer and there’s a whole bunch of different brokers and client libraries available. The use of a broker is potentially helpful in dealing with firewalling; clients and subscribers only need to talk to the broker, rather than requiring any direct connection.
With all that in mind I decided to set up a broker to play with the basics. I made the decision that it should run on my OpenWRT router - all the devices I want to hook up can easily see that device, and if it’s down then none of them are going to be able to get to a broker hosted anywhere else anyway. I’d seen plenty of info about Mosquitto and it’s already in the OpenWRT package repository. So I sorted out a Let’s Encrypt cert, installed Moquitto and created a couple of test users:
opkg install mosquitto-ssl
mosquitto_passwd -b /etc/mosquitto/mosquitto.users user1 foo
mosquitto_passwd -b /etc/mosquitto/mosquitto.users user2 bar
chown mosquitto /etc/mosquitto/mosquitto.users
chmod 600 /etc/mosquitto/mosquitto.users
I then edited /etc/mosquitto/mosquitto.conf and made sure the following are set. In particular you need cafile set in order to enable TLS:
port 8883
cafile /etc/ssl/lets-encrypt-x3-cross-signed.pem
certfile /etc/ssl/mqtt.crt
keyfile /etc/ssl/mqtt.key
log_dest syslog
allow_anonymous false
password_file /etc/mosquitto/mosquitto.users
acl_file /etc/mosquitto/mosquitto.acl
Finally I created /etc/mosquitto/mosquitto.acl with the following:
user user1
topic readwrite #
user user2
topic read ro/#
topic readwrite test/#
That gives me user1 who has full access to everything, and user2 with readonly access to the ro/ tree and read/write access to the test/ tree.
To test everything was working I installed mosquitto-clients on a Debian test box and in one window ran:
mosquitto_sub -h mqtt-host -p 8883 --capath /etc/ssl/certs/ -v -t '#' -u user1 -P foo
and in another:
mosquitto_pub -h mqtt-host -p 8883 --capath /etc/ssl/certs/ -t 'test/message' -m 'Hello World!' -u user2 -P bar
(without the --capath it’ll try a plain TCP connection rather than TLS, and not produce a useful error message) which resulted in the mosquitto_sub instance outputting:
test/message Hello World!
Trying:
mosquitto_pub -h mqtt-host -p 8883 --capath /etc/ssl/certs/ -t 'test2/message' -m 'Hello World!' -u user2 -P bar
resulted in no output due to the ACL preventing it. All good and ready to actually make use of - of which more later.
The excellent selection of Belfast Tech conferences
Yesterday I was lucky enough to get to speak at BelTech, giving what I like to think of as a light-hearted rant entitled “10 Stupid Reasons You’re Not Using Free Software”. It’s based on various arguments I’ve heard throughout my career about why companies shouldn’t use or contribute to Free Software, and, as I’m sure you can guess, I think they’re mostly bad arguments. I only had a 20 minute slot for it, which was probably about right, and it seemed to go down fairly well. Normally the conferences I would pitch talks to would end up with me preaching to the converted, but I felt this one provided an audience who were probably already using Free software but hadn’t thought about it that much.
And that got me to thinking “Isn’t it fantastic that we have this range of events and tech groups in Belfast?”. I remember the days when the only game in town was the Belfast LUG (now on something like its 5th revival and still going strong), but these days you could spend every night of the month at a different tech event covering anything from IoT to Women Who Code to DevOps to FinTech. There’s a good tech community that’s built up, with plenty of cross over between the different groups.
An indicator of that is the number of conferences happening in the city, with many of them now regular fixtures in the annual calendar. In addition to BelTech I’ve already attended BelFOSS and Women Techmakers this year. Product Camp Belfast is happening today. NIDevConf is just over a month away (I’ll miss this year due to another commitment, but thoroughly enjoyed last year). WordCamp Belfast isn’t the sort of thing I’d normally notice, but the opportunity to see Heather Burns speak on the GDPR is really tempting. Asking around about what else is happening turned up B-Sides, Big Data Belfast and DigitalDNA.
How did we end up with such a vibrant mix of events (and no doubt many more I haven’t noticed)? They might not be major conferences that pull in an international audience, but in some ways I find that more heartening - there’s enough activity in the local tech scene to make this number of events make sense. And I think that’s pretty cool.
subscribe via RSS